2024.01.06 - [AI/딥러닝] - [딥러닝] 파이토치(Pytorch)
[딥러닝] 파이토치(Pytorch)
1. 파이토치란? Tensorflow와 함께 머신러닝, 딥러닝에서 가장 널리 사용되는 프레임워크입니다. 초기에는 Torch라는 이름으로 Lua언어 기반으로 만들어졌으나, 파이썬 기반으로 변경한 것이 Pytorch입
caramelbottle.tistory.com
이번 포스팅은 파이토치(PyTorch)를 사용하여 논리 회귀 모델을 만들기 입니다.
논리 회귀 모델은 로지스틱 회귀(Logistic Regression) 모델과 같습니다.
이름은 회귀이지만 분류에 사용되는 모델입니다.
선형 회귀 공식으로부터 나왔기 때문에 논리 회귀라는 이름이 붙여졌다고 합니다.
로지스틱 회귀와 시그모이드(Sigmoid), 소프트맥스(Softmax)에 대한 내용은 이전 게시글을 참고해주세요!
2023.12.28 - [AI/머신러닝] - [머신러닝] 로지스틱 회귀(Sigmoid & Softmax)
[머신러닝] 로지스틱 회귀(Sigmoid & Softmax)
1. 로지스틱 회귀(Logistic Regression) 로지스틱 회귀는 이진 분류 문제를 해결하는 기법중 하나입니다. 분류 문제에 선형 모델이 사용되기 때문에 회귀라는 이름이 붙었다고 합니다. 0과 1을 분류하
caramelbottle.tistory.com
1. 단항 논리 회귀(Logistic Regression)
1-1. 데이터 생성 및 시각화
필요한 라이브러리를 가져옵니다. Layer와 비용함수를 사용하기 위한 nn과 최적화 함수를 사용하기 위한 optim이 필요합니다.
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
랜덤 시드를 설정해주겠습니다.
torch.manual_seed(2024)
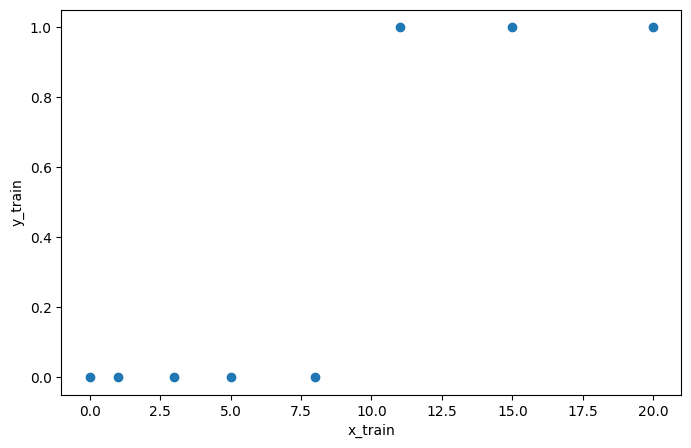
학습에 사용할 독립변수 데이터와 그 분류값인 종속변수 데이터를 생성해줍니다.
x_train = torch.FloatTensor([[0], [1], [3], [5], [8], [11], [15], [20]])
y_train = torch.FloatTensor([[0], [0], [0], [0], [0], [1], [1], [1]])
print(x_train.shape)
print(y_train.shape)
print(y_train)output>>
torch.Size([8, 1])
torch.Size([8, 1])
tensor([[0.],
[0.],
[0.],
[0.],
[0.],
[1.],
[1.],
[1.]])
데이터를 시각화해봅시다.
plt.figure(figsize=(8, 5))
plt.scatter(x_train, y_train)
plt.xlabel('x_train')
plt.ylabel('y_train')
plt.show()output>>
1-2. 모델 생성
시그모이드 수식은 다음과 같습니다.

sigmoid에 Linear함수가 들어가있는 형태입니다.
시그모이드 함수는 w와 b에 따라 그래프 모양이 바뀝니다.
입력 x에 해당하는 출력값은 0에서 1사이의 값입니다.
출력값이 보통 기준값인 0.5를 기준으로 크면 1 작으면 0로 분류하게 됩니다.
model = nn.Sequential(
nn.Linear(1, 1),
nn.Sigmoid()
)
Sequential은 신경망을 쉽게 정의하기 위한 컨테이너입니다.
nn.Linear는 시그모이드의 wx+b 부분을 정의한 것입니다.
그 출력이 다음 레이어에 입력으로 들어간다고 보시면 됩니다.
print(model)
# 학습전 파라미터
print(list(model.parameters()))output>>
Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): Sigmoid()
)
[Parameter containing:
tensor([[0.0634]], requires_grad=True), Parameter containing:
tensor([0.6625], requires_grad=True)]2. 비용 함수(Cost function)
비용함수는 성능과 관련이 있습니다.
비용함수는 모델의 예측과 실제값의 차이를 계산하며, 정확도를 계산하는 함수입니다.
손실함수(Loss function)와 비용함수(Cost function)는 보통 같은 의미로 사용된다고 하네요.
비용 함수의 수식은 다음과 같습니다.

[비용함수 링크]
2-1. BCELoss(Binary Cross Entropy Loss)
BCELoss는 이진 분류 문제에서 사용하는 손실함수입니다.
loss = nn.BCELoss()(y_pred, y_train)3. 단항 논리 회귀 모델 학습
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs} Loss: {loss:.6f}')output>>
Epoch: 0/1000 Loss: 0.836359
Epoch: 100/1000 Loss: 0.725281
Epoch: 200/1000 Loss: 0.645149
Epoch: 300/1000 Loss: 0.579139
Epoch: 400/1000 Loss: 0.524739
Epoch: 500/1000 Loss: 0.479715
Epoch: 600/1000 Loss: 0.442194
Epoch: 700/1000 Loss: 0.410667
Epoch: 800/1000 Loss: 0.383936
Epoch: 900/1000 Loss: 0.361067
Epoch: 1000/1000 Loss: 0.3413294. 다항 논리 회귀
단항 논리 회귀는 입력 변수가 하나인 분류 모델입니다.
다항 논리 회귀는 입력 변수가 두 개 이상인 분류 모델입니다.
4-1. 데이터 생성 및 시각화
x_train = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_train = [0, 0, 0, 1, 1, 1, 2, 2]
x_train = torch.FloatTensor(x_train)
y_train = torch.LongTensor(y_train)
print(x_train, x_train.shape)
print(y_train, y_train.shape)output>>
tensor([[1., 2., 1., 1.],
[2., 1., 3., 2.],
[3., 1., 3., 4.],
[4., 1., 5., 5.],
[1., 7., 5., 5.],
[1., 2., 5., 6.],
[1., 6., 6., 6.],
[1., 7., 7., 7.]]) torch.Size([8, 4])
tensor([0, 0, 0, 1, 1, 1, 2, 2]) torch.Size([8])
임의의 데이터는 로지스틱 회귀모델을 사용할 수 있게 어느정도 선형 관계를 가지도록 만들었습니다.
또한 분류 클래스를 3개로 하여 시그모이드가 아닌 다른 방법을 사용하여 분류를 해보겠습니다.
각 행의 평균과 출력의 관계를 그래프로 확인해봅시다.
row_means = torch.mean(x_train, dim=1)
plt.figure(figsize=(8, 5))
plt.scatter(row_means, y_train, color='r')
plt.xlabel('x_train')
plt.ylabel('y_train')
plt.show()output>>
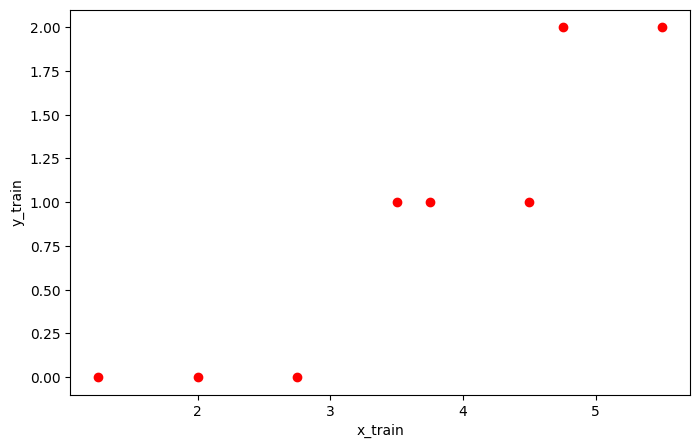
단항 로지스틱 회귀의 경우 분류 클래스가 0과 1로 시그모이드 함수로 분류가 가능했으나, 클래스가 3개 이상인 경우 시그모이드 함수로는 분류에 한계가 있습니다.
4-2. 모델 생성
독립변수의 항이 4개이면 nn.Linear()의 입력 차원을 4로 하면 됩니다.
출력 차원은 분류 클래스 갯수와 같게 하면 됩니다.
model = nn.Sequential(
nn.Linear(4, 3)
)
print(model)
print(list(model.parameters()))output>>
Sequential(
(0): Linear(in_features=4, out_features=3, bias=True)
)
[Parameter containing:
tensor([[ 0.4718, -0.3807, -0.3331, -0.1505],
[-0.2850, 0.1201, -0.0151, 0.2492],
[-0.3479, 0.0625, -0.3265, 0.2046]], requires_grad=True), Parameter containing:
tensor([ 0.4265, -0.0939, -0.1955], requires_grad=True)]
출력 차원을 분류 클래스 갯수와 같게 한 이유는 다중 분류에는 시그모이드(Sigmoid)가 아닌 소프트맥스(Softmax)가 사용되어야 하기 때문입니다.
코드를 보시면 소프트맥스를 활성화함수로 추가하지 않았습니다.
그 이유는 손실 함수인 CrossEntropyLoss()에 소프트맥스가 포함되어 있기 때문입니다.
4-3. 학습
loss = nn.CrossEntropyLoss()(y_pred, y_train)
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs} Loss: {loss:.6f}')output>>
Epoch: 0/1000 Loss: 1.212971
Epoch: 100/1000 Loss: 0.629261
Epoch: 200/1000 Loss: 0.556415
Epoch: 300/1000 Loss: 0.505015
Epoch: 400/1000 Loss: 0.462015
Epoch: 500/1000 Loss: 0.423341
Epoch: 600/1000 Loss: 0.386988
Epoch: 700/1000 Loss: 0.351581
Epoch: 800/1000 Loss: 0.316010
Epoch: 900/1000 Loss: 0.279698
Epoch: 1000/1000 Loss: 0.2470144-4. 예측
임의로 입력 데이터를 넣고 예측을 한 후에 결과를 소프트맥스(Softmax)를 통해 확률로 출력해봅시다.
x_test = torch.FloatTensor([[1, 7, 8, 7]])
y_pred = model(x_test)
print(y_pred)output>>
tensor([[-10.2333, 0.3633, 5.1844]], grad_fn=<AddmmBackward0>)
y_pred에 해당하는 값은 최적 함수를 통해 구해진 W, b로 계산된 값입니다.
이 값들을 Softmax에 넣으면 각 클래스에 포함될 확률을 반환합니다.
y_prob = nn.Softmax(1)(y_pred)
print(f'0일 확률: {y_prob[0][0]: .2f}')
print(f'1일 확률: {y_prob[0][1]: .2f}')
print(f'2일 확률: {y_prob[0][2]: .2f}')output>>
0일 확률: 0.00
1일 확률: 0.01
2일 확률: 0.99끝내며
로지스틱 회귀 모델을 PyTorch를 사용하여 만들어 보았습니다.
입력 변수의 개수에 따라 모델의 입력 차원을 적절하게 설정해야하고, 출력 변수 또한 마찬가지입니다.
이제 진짜 딥러닝에 발을 들여야할 때가 다가오고 있네요.
꾸준함 잃지 않고 공부해보도록 하겠습니다!
'AI > PyTorch' 카테고리의 다른 글
| [PyTorch-예제] 기온에 따른 지면 온도 예측 - 선형 회귀 (0) | 2024.01.08 |
|---|---|
| [PyTorch] 파이토치(PyTorch)로 선형 회귀 모델 만들기 (1) | 2024.01.08 |
| [PyTorch] 파이토치(Pytorch) (0) | 2024.01.06 |

댓글